Debugging Linux Module Loading with QEMU
My company uses the ETAS ES582.1 CAN adapters to interface with a CAN bus. Since recently, the kernel has mainline support for these devices (the etas_es58x driver). However, my work operating system of choice, Kali Linux, does not ship with a prebuilt kernel module for the devices out of the box. Hence, I needed to manually compile the module to use the devices under Kali. While doing so, I ran into binary compatibility issues and ended up debugging the module loading process with QEMU to determine the root cause. This blog post is a summary of the process. I first explain the QEMU VM installation process, explain the issues I encountered, and outline the debugging process to pinpoint the issue.
Spoiler: If you arrived at this post in hopes of fixing the error message below, try installing the
paholetool. On Kali, the required package is calleddwarves. If that doesn’t work, I invite you to follow this post and try debugging for yourself.
On the host, I used an Arch Linux installation. The QEMU VM ran the target operating system, a Kali Linux installation. All my attempts were made on Kernel version 5.14.16.
QEMU VM Setup
On Arch, I merely needed to install the qemu package to get started. I then set up the VM image and started the installation. For the image, I intentionally used the raw format because it can easily be mounted on the host side as a loop device for manipulation. Additionally, for filesystems like ext4 that support holes, only non-zero blocks in the file will take up disk space. I created a rather big image to accommodate the source code and debug package. The second command starts up the VM with KVM, 4GB of memory and inserts the Kali installation disk.
1
2
$ qemu-img create -f raw kali_hd2.raw 16G
$ qemu-system-x86_64 -boot order=d -drive file=kali_hd.raw,format=raw -m 4G -enable-kvm -cdrom kali-linux-2021.3a-installer-netinst-amd64.iso
I installed a minimal Kali version without desktop environment and no preinstalled pentesting tools to reduce the size. Next, I ran the VM without ISO and with enabled gdb stub for attaching the debugger later on:
1
$ qemu-system-x86_64 -boot order=d -drive file=kali_hd.raw,format=raw -m 4G -enable-kvm -s
Kernel Module Compilation
The next step was to actually compile the module inside the VM. I used the linux-source package for maximum compatibility with the prebuilt kernel. apt automatically pulled in Kali package version 5.14.16-1kali1.
1
2
3
4
$ sudo apt-get install build-essential libncurses5-dev libelf-dev libssl-dev
$ sudo apt-get install linux-source linux-headers-amd64
$ tar -xf /usr/src/linux-source-5.14.tar.xz
$ cd linux-source-5.14/
Next, I prepared the sources for compilation. I copied the configuration file and module symbol version file from the linux-headers package.
1
2
$ cp /usr/src/linux-headers-5.14.0-kali4-amd64/.config .
$ cp /usr/src/linux-headers-5.14.0-kali4-amd64/Module.symvers .
Since the module I wanted to compile was not enabled in the .config file, I manually enabled the module by adding the following line to the file:
1
CONFIG_CAN_ETAS_ES58X=m
Finally, I was able to compile the module. The first step in the series of commands checks the configuration file for completeness and queries the user for any missing configuration option. I stuck with the defaults.
1
2
3
4
$ make oldconfig
$ make prepare
$ make modules_prepare
$ make M=drivers/net/can/usb/etas_es58x/
Next I tried to insmod the new module and its dependencies for a quick test:
1
2
3
$ for i in can-dev usbcore crc16; do sudo modprobe $i; done
$ sudo insmod drivers/net/can/usb/etas_es58x/etas_es58x.ko
insmod: ERROR: could not insert module drivers/net/can/usb/etas_es58x/etas_es58x.ko: Invalid module format
As expected, the module insertion failed due to some unknown issue with the module. Next, I checked the kernel log:
1
2
$ sudo dmesg | tail -n 1
[ 2056.862808] module: x86/modules: Skipping invalid relocation target, existing value is nonzero for type 1, loc 00000000909cc68f, val ffffffffc087f984
The debug message was rather cryptic, but revealed that there seemed to be some issue with the symbol relocation during module linking. I dug up the kernel code responsible for loading the modules and took a closer look at the loading process.
Static analysis of the module loading process
From the debug message, I was able to trace the location in the code where the linking process failed. The message was printed from inside __apply_relocate_add in arch/x86/kernel/module.c. The function is responsible for applying relocations to ELF sections of the module.
A short excursion on relocations
In generic terms, a relocation links the reference of a symbol to its definition. As an example, if a kernel module wants to call a function like printk, which it does not provide itself, it must know the address at which the function is located. Since the address is not known at compile time, it must be dynamically inserted into the module at load time. The process of performing this search and replace is defined by a relocation.
The relocations that need to be applied to the kernel module at startup are stored in the ELF file along with code and data. For each section to which relocations must be applied, the module contains a .rela section with relocations. As an example, most modules feature a .text section that contains the compiled code of the module. The relocations for that section are stored in the .rela.text section.
Each relocation in a .rela section consists of several values:
- The location relative to the start of the target section at which the relocation must be applied.
- A link to the symbol that must be inserted at the specified location.
- The type of the relocation. Relocation types are specific to a processor and define how the symbol value must be inserted at the location.
- An addend, however this is not strictly relevant to this post
To give a quick example, below I list a relocation from the .rela.text section in the etas_es58x module:
1
2
Offset Info Type Sym. Value Sym. Name + Addend
000000000031 00c900000004 R_X86_64_PLT32 0000000000000000 memcpy - 4
The relocation specifies that the address of symbol memcpy must be placed at offset 0x31 relative to the beginning of the .text section.
Analysis of the relocation error
Below is the source code of __apply_relocate_add (arch/x86/kernel/module.c). The function applies all relocations contained in a single .rela section. For each relocation, it calculates the absolute address of the relocation in loc and the symbol value in val. The switch case statement that follows is responsible for applying the symbol value according to the relocation type. The function also performs a sanity check before it applies a relocation: it checks if the location in memory is properly initialized to zero. If not, it aborts with an error message.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
static int __apply_relocate_add(Elf64_Shdr *sechdrs,
const char *strtab,
unsigned int symindex,
unsigned int relsec,
struct module *me,
void *(*write)(void *dest, const void *src, size_t len))
{
unsigned int i;
Elf64_Rela *rel = (void *)sechdrs[relsec].sh_addr;
Elf64_Sym *sym;
void *loc;
u64 val;
DEBUGP("Applying relocate section %u to %u\n",
relsec, sechdrs[relsec].sh_info);
for (i = 0; i < sechdrs[relsec].sh_size / sizeof(*rel); i++) {
/* This is where to make the change */
loc = (void *)sechdrs[sechdrs[relsec].sh_info].sh_addr
+ rel[i].r_offset;
/* This is the symbol it is referring to. Note that all
undefined symbols have been resolved. */
sym = (Elf64_Sym *)sechdrs[symindex].sh_addr
+ ELF64_R_SYM(rel[i].r_info);
DEBUGP("type %d st_value %Lx r_addend %Lx loc %Lx\n",
(int)ELF64_R_TYPE(rel[i].r_info),
sym->st_value, rel[i].r_addend, (u64)loc);
val = sym->st_value + rel[i].r_addend;
switch (ELF64_R_TYPE(rel[i].r_info)) {
case R_X86_64_NONE:
break;
case R_X86_64_64:
if (*(u64 *)loc != 0)
goto invalid_relocation;
write(loc, &val, 8);
break;
case R_X86_64_32:
if (*(u32 *)loc != 0)
goto invalid_relocation;
write(loc, &val, 4);
if (val != *(u32 *)loc)
goto overflow;
break;
case R_X86_64_32S:
if (*(s32 *)loc != 0)
goto invalid_relocation;
write(loc, &val, 4);
if ((s64)val != *(s32 *)loc)
goto overflow;
break;
case R_X86_64_PC32:
case R_X86_64_PLT32:
if (*(u32 *)loc != 0)
goto invalid_relocation;
val -= (u64)loc;
write(loc, &val, 4);
#if 0
if ((s64)val != *(s32 *)loc)
goto overflow;
#endif
break;
case R_X86_64_PC64:
if (*(u64 *)loc != 0)
goto invalid_relocation;
val -= (u64)loc;
write(loc, &val, 8);
break;
default:
pr_err("%s: Unknown rela relocation: %llu\n",
me->name, ELF64_R_TYPE(rel[i].r_info));
return -ENOEXEC;
}
}
return 0;
invalid_relocation:
pr_err("x86/modules: Skipping invalid relocation target, existing value is nonzero for type %d, loc %p, val %Lx\n",
(int)ELF64_R_TYPE(rel[i].r_info), loc, val);
return -ENOEXEC;
overflow:
pr_err("overflow in relocation type %d val %Lx\n",
(int)ELF64_R_TYPE(rel[i].r_info), val);
pr_err("`%s' likely not compiled with -mcmodel=kernel\n",
me->name);
return -ENOEXEC;
}
This error message is the same as the one that was displayed when I tried to load my freshly-compiled module. Apparently, the dynamic linker encountered a relocation where the target address already held a non-zero value. However, a quick check with readelf -a etas_es58x.ko revealed that none of the relocation targets in the respective sections of the ELF file held a non-zero value. Consequently, the location had to have been manipulated at runtime while the module was being loaded. Unfortunately, the error message itself did not yield any useful information, like the section in which the issue occurred or the name of the affected symbol. Hence, I decided to investigate the issue further by debugging the function at runtime using QEMU.
Dynamic analysis with QEMU and GDB
In order to debug the kernel, I needed to set up gdb, acquire an ELF file of the compiled kernel that contained debug symbols, and disable KASLR, the kernel address space layout randomization.
Setup
I normally run gdb with gef which provides a convenient context print during debugging as well as some advanced features for memory inspection.
Kali has a convenient package called linux-image-amd64-dbg. It contains an ELF file of the kernel with debugging symbols. However, for the debugging I needed both the source code as well as the ELF file on the host to connect to the gdb server stub of QEMU. Fortunately, with the raw image format, it was very easy to mount and copy data from the image:
1
2
3
4
5
6
7
8
$ sudo losetup -f kali_hd.raw
$ sudo partprobe /dev/loop0
$ sudo mount /dev/loop0p1 /mnt
$ cp -r /mnt/home/kali/linux-source-5.14/ .
$ cd linux-source-5.14/
$ cp /mnt/usr/lib/debug/boot/vmlinux-5.14.0-kali4-amd64 .
$ sudo umount /mnt
$ sudo losetup -D
I also loaded the ELF file of the kernel image into Ghidra for analysis. This allowed me to look around and do cross-referencing more easily than I was able to do from inside gdb.
Lastly, I needed to disable the kernel address space layout randomization. This can be done by booting the kernel with the keyword nokaslr. I edited /etc/default/grub in the VM and added nokaslr to the following line in the file:
1
GRUB_CMDLINE_LINUX="nokaslr"
Then I recreated the grub configuration file:
1
$ sudo update-grub
Breaking at the failing function
I started the VM with the -s flag to start a gdb server on localhost:1234. Then I ran gdb and connected to the server:
1
$ gdb ./vmlinux-5.14.0-kali4-amd64
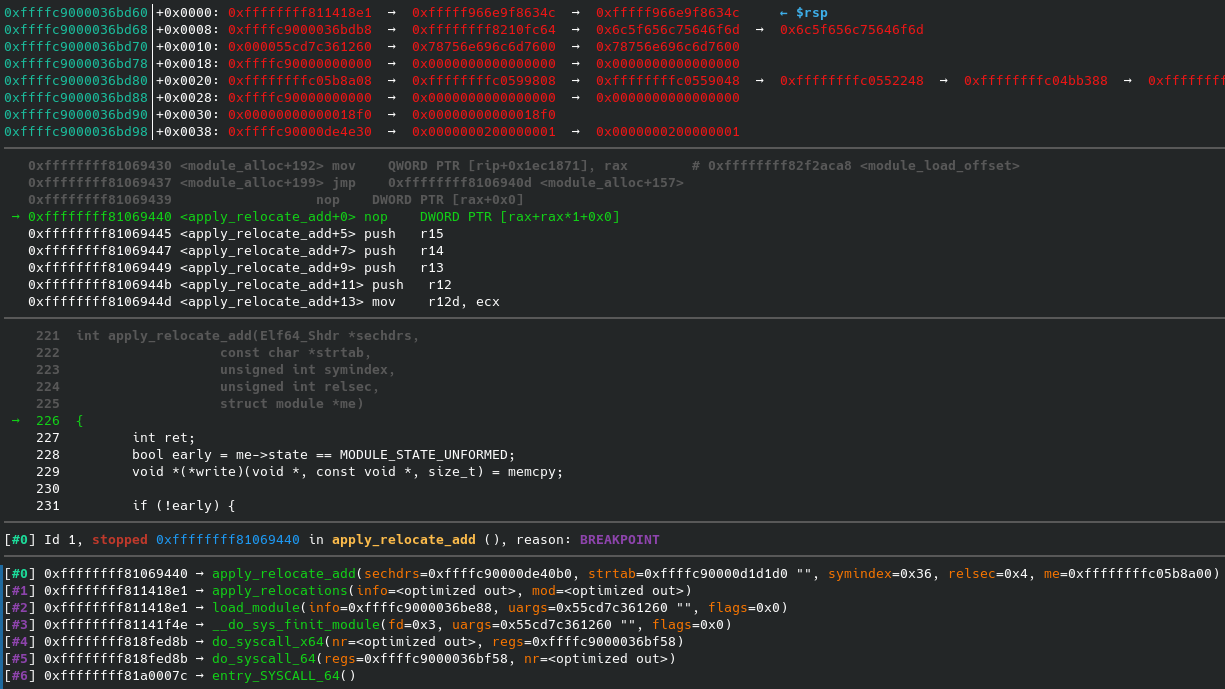
My plan was to pinpoint the relocation section and symbol that were causing the error condition by breaking at the error handler. However, due to compiler optimizations, most stack-based variable storage had been optimized away. The index of the relocation section relsec was passed into the function in the $ecx register but dropped after the absolute address of the section header had been calculated. Hence, I added two breakpoints in __apply_relocate_add. I added one breakpoint at the function start and another breakpoint at the error handler (the exact address of which I was able to determine with Ghidra). This setup allowed me to break at the function prologue to intercept the call parameters. If the second breakpoint hit right afterwards I knew that the last seen section was the offending one.
1
2
3
4
target remote localhost:1234
break apply_relocate_add
break *(apply_relocate_add+0x85a08c)
continue
The offending module relocation
I loaded the module inside the VM to trigger the breakpoint. At iteration relsec == 0x23, the second breakpoint hit, meaning that the error occurred there. The relocation section with index 0x23 was .rela.gnu.linkonce.this_module. The section contains the module struct with information (such as the name) about the module. The struct is kept in memory by the kernel and filled with runtime information. The relocation section for it featured two entries:
1
2
3
Offset Info Type Sym. Value Sym. Name + Addend
000000000138 00d400000001 R_X86_64_64 0000000000000000 init_module + 0
000000000340 00c800000001 R_X86_64_64 0000000000000000 cleanup_module + 0
The relocations tell the kernel to place the address of the init_module and the cleanup_module function at the specified offsets in the struct. One of the two relocations failed, however I didn’t yet know which one of the two. Fortunately, according to the decompiled source and assembly from Ghidra, the counter variable i in __apply_relocate_add had been placed in register r13 by the compiler, and the register was not written to for any other purpuses except the counter. This allowed me to simply dump the contents with p $r13 when the debugger hit the second breakpoint. The issue was with the second relocation for cleanup_module at index i == 1.
Tracing struct module write accesses
The next thing I wanted to try out was to determine what data was being written to the location. Since the offset was initialized to zero in the ELF file, it must have been written to directly before the relocation. I noticed that the module struct was first accessed quite early in the module loading process in setup_load_info of module.c:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
static int setup_load_info(struct load_info *info, int flags)
{
...
info->index.mod = find_sec(info, ".gnu.linkonce.this_module");
if (!info->index.mod) {
pr_warn("%s: No module found in object\n",
info->name ?: "(missing .modinfo section or name field)");
return -ENOEXEC;
}
/* This is temporary: point mod into copy of data. */
info->mod = (void *)info->hdr + info->sechdrs[info->index.mod].sh_offset;
...
}
In the last line, info->mod is set to point to the location of the gnu.linkonce.this_module section. Successive access to the struct always uses the reference stored in info. As the comment explains, the address is only temporary since the module still has to be copied to its final location.
In order to determine the address of section gnu.linkonce.this_module and hence the address of the module struct, I set a breakpoint in load_module because setup_load_info had been optimized away.
1
b *(load_module + 0x32d)
Once the breakpoint hit, I set a custom watch point to break whenever the pointer to the cleanup_module function was being manipulated:
1
2
3
4
5
$ p $r13
$5 = 0xffffc90002e52c80
$ awatch *(0xffffc90002e52c80 + 0x340)
Hardware access (read/write) watchpoint 2: *(0xffffc90002e52c80 + 0x340)
$ continue
The first time the breakpoint hit was in memcpy when the entire section was being copied to its final location in kernel memory. I added a new watchpoint to the same section offset in target memory. The new breakpoint hit in load_module+0x1025, which Ghidra presented as the following decompiled C code:
1
2
3
4
5
6
7
8
*(int **)(piVar37 + 0xce) = piVar37 + 0xcc;
*(int **)(piVar37 + 0xcc) = piVar37 + 0xcc;
*(int **)(piVar37 + 0xd0) = piVar37 + 0xd0;
*(int **)(piVar37 + 0xd2) = piVar37 + 0xd0;
LOCK();
piVar37[0xd6] = piVar37[0xd6] + 1;
__mutex_init(piVar37 + 0x3a,s_&mod->param_lock_ffffffff8210fe43, &__key.7);
uVar11 = find_sec(info,s___param_ffffffff8210fe54);
The code writes some unknown data to the pointer of cleanup_module. Directly afterwards, it initializes a mutex and calls the find_sec function to determine the index of the __param section. There was only one location in the module loading code where this disassembly could have originated from - somewhat in the middle of the load_module code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
/* To avoid stressing percpu allocator, do this once we're unique. */
err = percpu_modalloc(mod, info);
if (err)
goto unlink_mod;
/* Now module is in final location, initialize linked lists, etc. */
err = module_unload_init(mod);
if (err)
goto unlink_mod;
init_param_lock(mod);
/*
* Now we've got everything in the final locations, we can
* find optional sections.
*/
err = find_module_sections(mod, info);
if (err)
goto free_unload;
The mutex is initialized in init_param_lock and find_sec("__param") is executed in find_module_sections. Hence, the modification of the cleanup_module pointer had to occur in the module_unload_init function. And indeed, the function initialized two linked lists in struct module:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/* Init the unload section of the module. */
static int module_unload_init(struct module *mod)
{
/*
* Initialize reference counter to MODULE_REF_BASE.
* refcnt == 0 means module is going.
*/
atomic_set(&mod->refcnt, MODULE_REF_BASE);
INIT_LIST_HEAD(&mod->source_list);
INIT_LIST_HEAD(&mod->target_list);
/* Hold reference count during initialization. */
atomic_inc(&mod->refcnt);
return 0;
}
In assembly, the initialization operation is even more clearly visible.
1
2
3
4
5
6
7
fff811405d7 LEA RAX,[R13 + 0x330]
fff811405de MOV dword ptr [R13 + 0x358],0x1
fff811405e9 MOV qword ptr [R13 + 0x338],RAX
fff811405f0 MOV qword ptr [R13 + 0x330],RAX
fff811405f7 LEA RAX,[R13 + 0x340]
fff811405fe MOV qword ptr [R13 + 0x340],RAX
fff81140605 MOV qword ptr [R13 + 0x348],RAX
Register $r13 contained the address of the module struct. The forward and backward pointers in each list were initialized to loop back to the list instance. Interestingly, the second of the two lists was clearly leaking into the cleanup_module pointer, which the relocation operation expected to be located at offset 0x340 of the struct. In the struct definition, the two linked lists were directly bordering on the cleanup_module function pointer, here called exit:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct module {
// ...
#ifdef CONFIG_MODULE_UNLOAD
/* What modules depend on me? */
struct list_head source_list;
/* What modules do I depend on? */
struct list_head target_list;
/* Destruction function. */
void (*exit)(void);
atomic_t refcnt;
#endif
// ...
}
To summarize the finding, the kernel module loading code and the relocations in the module were using two different, binary incompatible definitions of struct module. In the version known to the module, the exit function pointer had moved to the front of the struct by 16 Bytes.
The root cause
Although I had made an exact copy of the kernel configuration used by the Kali package maintainers, apparently some configuration options were manipulating the struct module definition and causing the offset. I made a diff of my local .config file and the one that shipped with the source package:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
CONFIG_DEBUG_KERNEL=y
--- /usr/src/linux-headers-5.14.0-kali4-amd64/.config 2021-11-05 11:54:48.000000000 +0100
+++ .config 2021-11-22 21:41:25.519431077 +0100
@@ -2,9 +2,9 @@
# Automatically generated file; DO NOT EDIT.
# Linux/x86 5.14.16 Kernel Configuration
#
-CONFIG_CC_VERSION_TEXT="gcc-10 (Debian 10.3.0-12) 10.3.0"
+CONFIG_CC_VERSION_TEXT="gcc (Debian 11.2.0-10) 11.2.0"
CONFIG_CC_IS_GCC=y
-CONFIG_GCC_VERSION=100300
+CONFIG_GCC_VERSION=110200
CONFIG_CLANG_VERSION=0
CONFIG_AS_IS_GNU=y
CONFIG_AS_VERSION=23700
@@ -14,6 +14,7 @@
CONFIG_CC_CAN_LINK=y
CONFIG_CC_CAN_LINK_STATIC=y
CONFIG_CC_HAS_ASM_GOTO=y
+CONFIG_CC_HAS_ASM_GOTO_OUTPUT=y
CONFIG_CC_HAS_ASM_INLINE=y
CONFIG_CC_HAS_NO_PROFILE_FN_ATTR=y
CONFIG_IRQ_WORK=y
@@ -1893,7 +1894,7 @@
CONFIG_CAN_8DEV_USB=m
CONFIG_CAN_EMS_USB=m
CONFIG_CAN_ESD_USB2=m
-# CONFIG_CAN_ETAS_ES58X is not set
+CONFIG_CAN_ETAS_ES58X=m
CONFIG_CAN_GS_USB=m
CONFIG_CAN_KVASER_USB=m
CONFIG_CAN_MCBA_USB=m
@@ -9716,8 +9717,6 @@
CONFIG_DEBUG_INFO_DWARF_TOOLCHAIN_DEFAULT=y
# CONFIG_DEBUG_INFO_DWARF4 is not set
CONFIG_DEBUG_INFO_BTF=y
-CONFIG_PAHOLE_HAS_SPLIT_BTF=y
-CONFIG_DEBUG_INFO_BTF_MODULES=y
# CONFIG_GDB_SCRIPTS is not set
CONFIG_FRAME_WARN=2048
CONFIG_STRIP_ASM_SYMS=y
@@ -9747,6 +9746,8 @@
CONFIG_ARCH_HAS_UBSAN_SANITIZE_ALL=y
# CONFIG_UBSAN is not set
CONFIG_HAVE_ARCH_KCSAN=y
+CONFIG_HAVE_KCSAN_COMPILER=y
+# CONFIG_KCSAN is not set
# end of Generic Kernel Debugging Instruments
CONFIG_DEBUG_KERNEL=y
Of all configuration options that were different in both versions, option CONFIG_DEBUG_INFO_BTF_MODULES was the most interesting to my case. If enabled, it added two members to struct module:
1
2
3
4
5
6
7
8
struct module {
// ...
#ifdef CONFIG_DEBUG_INFO_BTF_MODULES
unsigned int btf_data_size;
void *btf_data;
#endif
// ...
}
Given the alignment requirements of amd64, the compiler would likely add 4 Byte of padding between the int and the void pointer, resulting in a size of 16 Byte for the two members. At that point I was fairly certain I had found the culprit for my issues. The only thing I did not know was why the option had been disabled.
I retraced my compilation steps to determine why the option was disabled. The option seemed to be magically turned off after executing make oldconfig. After digging a little in the documentation, I found the reason: I was missing the pahole tool in my PATH. The Makefile automatically disabled the option if pahole was not found.
I installed the dwarves package in Kali, recompiled the kernel module, and called insmod to insert the module into the kernel. And behold:
1
2
3
4
5
$ lsmod | grep etas
etas_es58x 53248 0
usbcore 331776 1 etas_es58x
can_dev 40960 1 etas_es58x
crc16 16384 2 etas_es58x,ext4
The module was happy and alive.
Takeaway Message
When compiling a kernel module: always make sure that the configuration file doesn’t change while you’re not looking. This scenario wasn’t something I was aware of until now. And frankly, I do not consider it to be good design. Of course I don’t have the entire picture, but I believe a missing dependency should cause a build to fail fast, not produce incompatible artifacts.